
Abstract
Archaeological fragment processing is crucial to support the analysis of pictorial contents of broken artifacts. In this paper, we focus on the unexplored task of semantic segmentation of fresco fragments. This task enables the extraction of semantic information from a fragment, facilitating subsequent tasks like fragment classification or reassembly. We introduce a semantic segmentation dataset of fresco fragments acquired at the Pompeii Archeological Site, accompanied by baseline models. Additionally, we introduce a supplementary task of fragment cleaning, providing a dataset with the detection of manual annotations of archaeological marks that require restoration before further analysis. Our experiments, using standard metrics and state-of-the-art baselines, demonstrate that semantic segmentation of fresco fragments is feasible, paving the way toward more complex activities that require a semantic understanding of fragmented artifacts.
Datasets
We released two datasets for fragment processing tasks. They consist of high-quality photorealistic renderings of scanned 3D fragments from the PPompeii Archeological Site.
BoFF Dataset

Archaeologists make temporary markings on the intact surface of fresco fragments as reminders during the fresco
anastylosis task, particularly when dealing with a large number of fragments. These markings include black marks
on the borders, indicating neighboring relationships between fragments, and arrows showing the direction
of construction lines typically visible only on the backside of the fragments. While useful for
archaeologists, these markings can be misleading and introduce bias in computational tasks. Thus,
cleaning the dataset is crucial to ensure unbiased evaluations of different approaches.
The BoFF dataset is specifically designed for the automatic detection of manual markings in bounding boxes to
facilitate their removal through inpainting. It contains 115 fragment images with 405 annotations of
bounding boxes covering manual markings on the fragment images.
MoFF Dataset
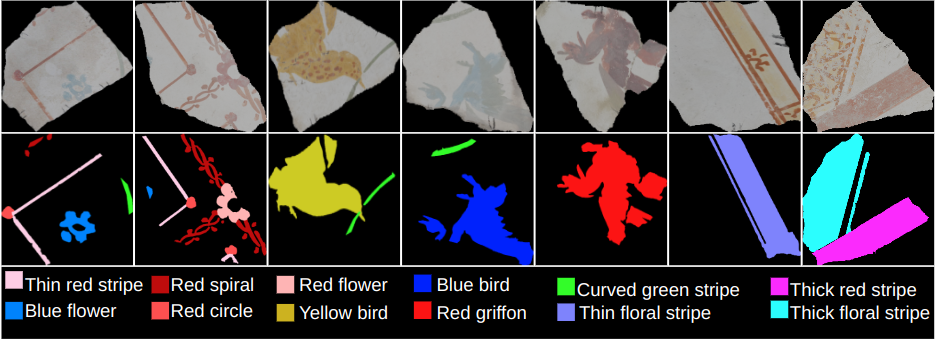
The MoFF dataset is curated to support the extraction and categorization of motifs from fragmented frescoes, with a particular focus on Roman wall paintings from the Pompeii archaeological site. These frescoes include recurring geometric colored patterns, known as motifs. The dataset contains 405 high-resolution images extracted from two distinct fresco ceilings. The dataset provides ground truth annotations with pixel-wise segmentation masks, precisely highlighting motifs from 12 different classes. The annotations are available in two distinct setups: a 3-class annotation, comprising image background, fragment background, and motif class, and a more detailed 12-class annotation, exclusively focusing on distinct motif types. Pixel annotations were prepared using the segments.ai platform.
Request to access MoFF dataset